Rethinking content extraction for audio and video automation

Article-to-audio and video automation only works if you extract the right content first.
For publishers, this step is a constant source of friction. Modern news pages are dynamic, JavaScript-heavy, and packed with non-editorial elements, but most content extraction methods still rely on fixed HTML rules tied to page structure.
This can result in navigational elements, ads, and other unwanted elements appearing in audio and video assets. Or your team having to spend time specifying content manually.
That’s why we built a more reliable content extraction method.
Introducing automatic extraction
BeyondWords now offers automatic extraction, which is powered by AI. Our model interprets the context of a page and accurately identifies which text and images actually belong to the article, even when layouts vary or content is rendered dynamically.
The extracted content then flows through the rest of the BeyondWords workflow to generate audio and video, based on your settings.
Automatic extraction delivers practical benefits for publishers:
- Cleaner, more faithful audio and video versions of your articles;
- Reduced need for per-site configuration and manual tuning;
- Better adaptability across layouts, frameworks, and CMSs; and
- More reliable scaling across diverse publisher environments.
Solving the content extraction problem took a lot of engineering effort. We evaluated several tools, compared benchmarks, and iterated several times to finally arrive at a solution that yields high-quality results.
Optional filters and metadata controls are available for publishers who want to refine what content is extracted, but most sites won’t need them.
We also added controls that allow publishers to limit which domains the workflow is allowed to run and to set HTTP headers to bypass paywalls, so our servers always have access to the necessary content.
Automatic extraction in action
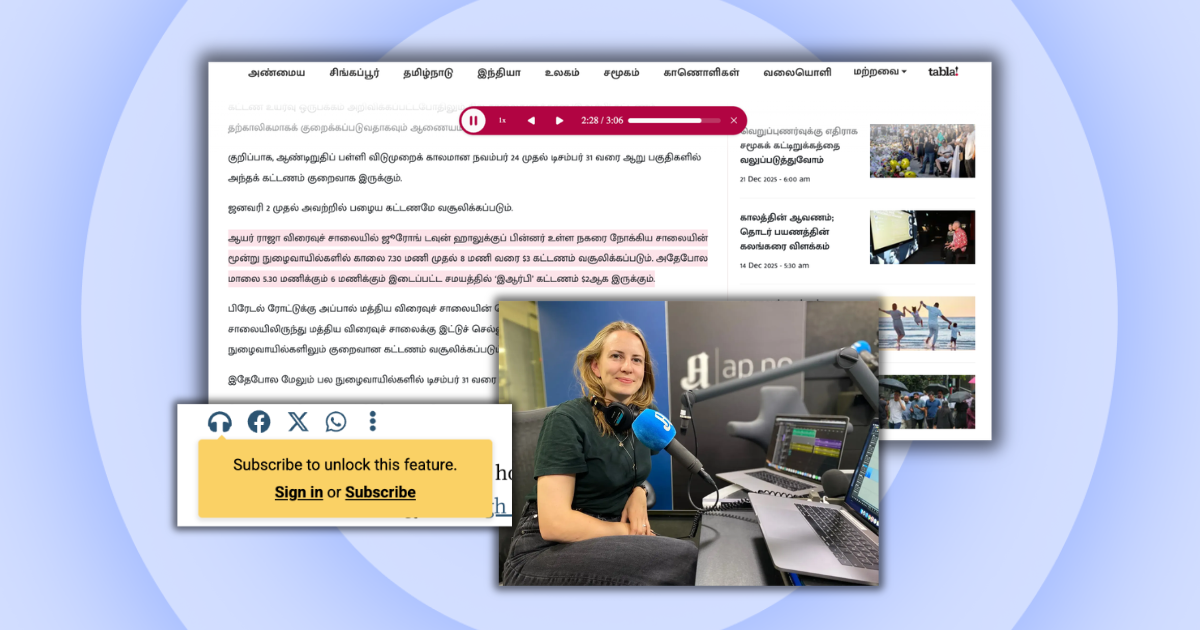
To give you an example, we ran a media-rich news article through BeyondWords using the automatic extraction setting.
The screenshot below highlights which parts of the article were used to generate the audio and/or video versions—and which parts were automatically excluded.
BeyondWords accurately identified the editorial text and images for inclusion in the audio and video versions.
Unwanted elements—such as the navigation menu, advertising banner, author byline, key points, call-to-action button, image caption, content sidebar, and footer—were rightfully excluded.
And this was all done automatically.
The next step: Developing a change detection algorithm
Improving initial extraction only solves part of the problem. For audio and video automation to meet newsroom needs, article updates must be detected and reflected accurately.
A potential solution is to repeatedly fetch the page and rerun the entire extraction and AI pipeline, but this method is inefficient and could be unstable. It can also introduce unnecessary costs—especially when changes are minor or purely superficial.
To avoid this, we developed a change detection algorithm. This compares newly fetched HTML with the content extracted previously to determine what has changed.
So, audio and video stay in sync with article edits, without manual intervention or excessive processing.
Built to fit your publishing stack
Automatic content extraction is built directly into our Magic Embed integration, making it easy to enable audio and video across your publication.
Add a small script to your website, then let BeyondWords handle the rest—including content extraction, audio and video generation, distribution, monetization, and analytics. You can manage settings and content centrally through your BeyondWords dashboard.
Want to see how it works in practice? Book a demo today.