Augmenting Amazon Polly with SpeechKit for better audio articles

Please note that this post was published before SpeechKit rebranded to BeyondWords.
Improving text-to-speech with automatic SSML tagging
In 2018, 24.8 million people in the UK (45.5%) listened to online audio. Our belief is that this number will continue to grow and with it the percentage of newsreaders who will listen to audio narratives, such as news articles.
SpeechKit was designed to help news publishers pivot-to-audio, via audio versions of their news stories, without the time and cost required to narrate them — providing newsreaders with the choice of listening to news articles when reading is undesirable, boosting engagement with audio-streaming native demographics.
To keep costs low and the audio scalable we’re using the newly released, neural voices, available through the Amazon text-to-speech (TTS) service (Amazon Polly), to generate lifelike audio.
However for news brands seeking to use TTS, like Amazon Polly, to deliver the best audio experience they can, at scale, they’ll need to use SSML (speech-synthesis-markup) tags. Not using SSML will, without a doubt, lead to a sub-par audio experience and dissatisfied listeners.
SSML gives you additional control over how Amazon generates speech from text. Enhancing audio with SSML involves inserting specific tags into the text. Doing this manually for a single news article can take time, doing so for all published articles is almost impossible.
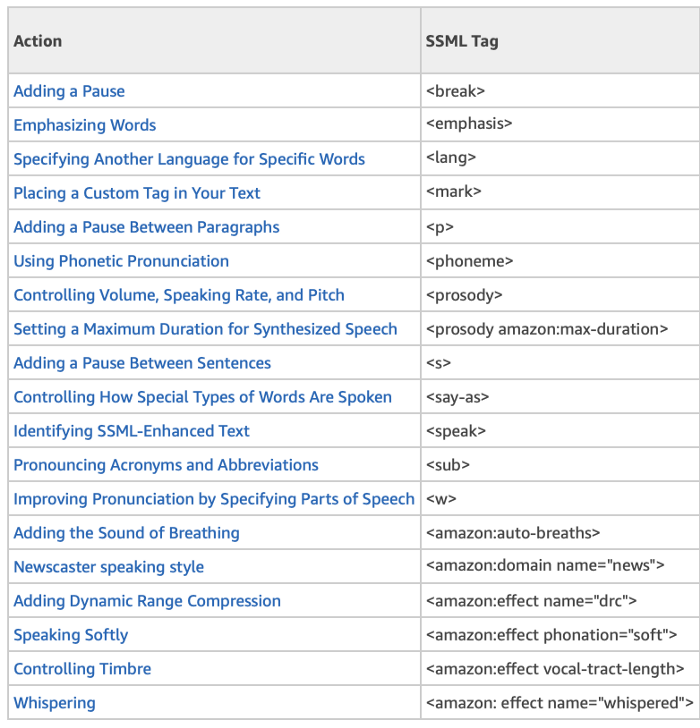
Amazon Polly supports SSML tags (see table below), but the service does not insert them for you. This usually requires context and Amazon did not develop Amazon Polly just for the news industry.
We’ve developed a middle-layer, called NewsNet, that, amongst other things, automates the SSML tagging process for news articles using a combination of rule-based and neural-network-based techniques.
This post will demonstrate the importance of using SSML when it comes to converting news articles into audio, and highlight the benefit to publishers of using SpeechKit to automate this process.
Amazon Polly accepts inputs as either plain text or SSML. For publishers using SpeechKit, NewsNet automatically cleans and converts all plain text from news articles into SSML and encloses SSML tags around paragraphs, sentences, specific words and phrases, amongst a few other things we’ll discuss in another post.
<speak>, <amazon:domain name=”news”>
The first step is to wrap the text into a <speak> tag. This tells Amazon Polly to process the input as SSML. The second step is to indicate to Amazon Polly that the text should be read as a news item using the <amazon:domain name=”news”> tag. The third step, and this is where NewsNet starts to shine, is to tokenize all words, sentences and phrases in the text and apply specific SSML tags to them using either our hardcoded rules or neural nets.
<p>, <s>
The first of these is the <p> and <s> tags that indicate whether a string of text is a sentence or paragraph to ensure that appropriate pauses are inserted into the speech — periods are not always reliable segmentation points in news stories.
Other SSML tags inserted using NewsNet include, but are not limited to, <phoneme>, <sub>, <say-as>, <lang> and <w> tags.
<phonemes>
In some cases, Amazon Polly struggles to pronounce specific words. This is quite common with brands, or in the case below with the president of South Africa. Over time we’ve added hundreds of words, common in the news, and their corrected pronunciation, to NewsNet so that they are detected, tagged, with the phoneme tag, and pronounced correctly appropriately.
Cyril Ramaphosa is a South African politician and the fifth and current President of South Africa.
<speak><amazon:domain name="news"><p><s>Cyril <phoneme alphabet="ipa" ph="ˌræməˈpoʊsə">Ramaphosa </phoneme> is a South African politician and the fifth and current President of South Africa.</s></p></amazon:domain></speak>
<sub>, <say-as>
Different news domains use different acronyms and abbreviations, that when spoken might sound unusual. NewsNet detects them, and using SSML, instructs Amazon Polly to expand them into their full spoken form using the <sub> tag or the <say-as> tag to describes how the text should be interpreted.
Oil prices leave little doubt about the strong growth coming from US oil in 2H19.
We maintain our exit-2019 production estimate of about 12.9 million bpd.
<speak><amazon:domain name="news"><p><s>Cyril <phoneme alphabet="ipa" ph="ˌræməˈpoʊsə">Ramaphosa</phoneme> is a South African politician and the fifth and current President of South Africa.</s></p></amazon:domain></speak>
As part of the scale down, the company will repurchase approximately 54 million tokens sold during its $17 million ICO from those that participated in the crowd-sale.
<speak><amazon:domain name="news"><p><s>As part of the scale down, the company will repurchase approximately 54 million tokens sold during its $17 million <say-as interpret-as="spell-out">ICO</say-as> from those that participated in the crowd-sale.</s></p></amazon:domain></speak>
<lang>
TTS services can struggle when it comes to pronouncing foreign language words and phrases in news articles (quite common!). NewsNet detects foreign language words and phrases and encloses a pair of <lang> tags around them to ensure the appropriate pronunciation.
Hello, my name is Jørgen.
<speak><amazon:domain name="news"><p><s>Hello, my name is <lang xml:lang="da-DK">Jørgen</lang>.</s></p></amazon:domain></speak>
<w>
Should it be read or read? This information comes naturally to readers but can be a curve ball for text-to-speech. NewsNet detects the correct pronunciation based on the part of speech and uses the <w> tag to specify this.
You only live once.
Published on BusinessLive.
<speak><amazon:domain name="news"><p><s>You only <w role="amazon:VB">live</w> once.</s><s>Published on Business<w role="amazon:NN">LIVE</w></s></p></amazon:domain></speak>
Beyond SSML
NewsNet does more than just automate the SSML tagging process. We found embedded tweets, videos (interviews) and “read more” links to be common elements in news articles that can throw off Amazon Polly and other TTS services. To resolve this NewsNet reformats tweets to improve how they are read, extracts spoken audio from videos and inserts the audio into the TTS generated audio, and strips sentences that have zero relevance to an article, such as “read more” links.
Conclusion
SpeechKit was developed to automate the audio needs of any news publishers wishing to serve audio alongside their news stories. It can be connected to any CMS, automatically embeds audio players into news articles, tracks audio engagement with real-time analytics and can be monetised with audio ads.
More about SpeechKit
At SpeechKit we’re helping 100s of news publishers to automate audio versions of their content efforts. Sign up for a free trial and instantly start creating audio for the next generation of news consumer.