How we view the text-to-speech audio market

Please note that this post was published before SpeechKit rebranded to BeyondWords.
The speech services market is young but already being disrupted. How do you compare company X or company Y in such a fast moving environment?
In this post, we lay out how we see this rapidly evolving market and what differentiates one company from another. First, some background...
Text-to-speech has often been overlooked as a revolutionary new media format. Over recent years, as with much nascent AI, text-to-speech has been scrutinized over error rates, poor voice quality, and its "robotic-ness". After four years of working to improve this technology, listening through hours upon hours of audio data, our team is well versed in these imperfections.
However, great improvements have been made - by our team and by our peers. Last year, Nic Newman from the Reuters Institute predicted audio articles would become "standard". New neural voices from SpeechKit, Amazon, and Google, among others, are coming closer to human speech than could have ever been imagined. Furthermore, text-to-speech is starting to show very real results.
The average engagement time of a listener is more than four times that of a non-listener.
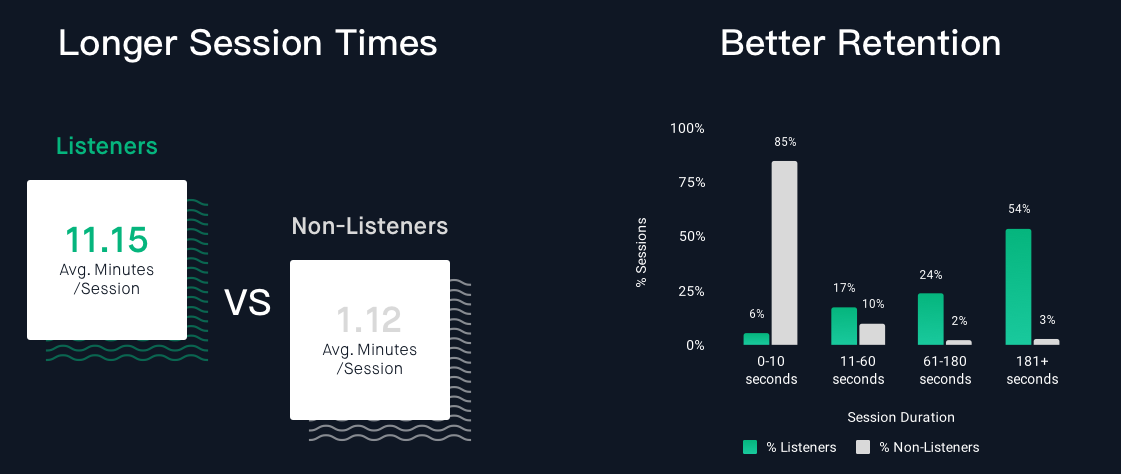
Text-to-speech is being adopted to improve customer value and fast-track digital transformation. Below we’ve segmented the market into three categories to make for easier comparison.
Cloud service APIs
Services such as Amazon Polly, Google WaveNet and IBM Watson provide text-to-speech APIs as part of their cloud service platforms. These products have been developed over the last 10–15 years, producing some of the most robust voices on the market.
Early adopters, such as Bloomberg and The Globe and Mail, adopted Amazon Polly across their publishing to give their readers the option to listen. Whilst high-quality, these services lack utility and customization; they’ve produced very powerful APIs, yet haven’t created any tools (hosting, CMS integrations, analytics, monetization) to help publishers get the most from text-to-speech.
- Strengths: Reliability, voice-quality, cost
- Weaknesses: Ease of integration, customization, publishing tools
Custom voice startups
Speech startups, such as Resemble and Sonantic, aim to out-compete those cloud services mentioned above by creating custom synthetic voices. These companies also have deep expertise in machine learning, developing high-quality voices for sectors such as gaming and customer service.
Similarly to cloud services, whilst these companies have developed advanced APIs, they’ve neglected publishing tools. Neither of these examples provides audio distribution tools, analytics or monetization options for publishing at scale.
- Strengths: Voice quality, customization, ease of integration
- Weaknesses: Publishing tools, cost, scalability
Other text-to-speech startups
Startups such as Trinity Audio and Play.ht are our most direct competitors. These, like ourselves, are developing tools around text-to-speech, creating value for publishers and bloggers.
Trinity Audio have focused on monetizing APIs created by those cloud services mentioned above. They’ve built ad insertion technology and partnered with multiple audio DSPs to improve fill-rates and potential CPMs. Their business model aims to provide revenue back to publishers who adopt their tech, while they take a cut. Whilst this is sound in principle, we believe a focus on voice quality, infrastructure and customer service most benefit our customer’s long term.
- Strengths: Monetization, cost, scalability
- Weaknesses: Ease of integration, voice quality, customization
SpeechKit
In comparison, SpeechKit has focused on becoming the full-stack service for automated audio publishing. We help news publishers, institutions, and corporate businesses publish their written content in audio, automatically and at scale.
We believe that improving access to quality content, through seamless audio integrations, is the real power of text-to-speech. Our strengths lie in building scalable products, using domain-specific voices that improve the effectiveness of digital publishing.
We’ve battle-tested our products across 150+ news sites and built out tools including analytics, APIs, SDKs and an audio CMS. With less than 1% of the world’s content currently available in audio, we have high hopes for the coming years!
To check it out for yourself, schedule a demo with a team member today.

